import os
import polars as pl
import imageio.v3 as iio
import grain.python as grain
import dm_pix as pix
import numpy as np
from jax import random
metadata = pl.read_parquet('metadata.parquet')
metadata_train = metadata.filter(pl.col('is_training_img') == 1)
metadata_val = metadata.filter(pl.col('is_training_img') == 0)
cleaned_img_dir = os.path.join(base_dir, 'cleaned_images')
class NABirdsDataset:
"""NABirds dataset class."""
def __init__(self, metadata, data_dir):
self.metadata = metadata
self.data_dir = data_dir
def __len__(self):
return len(self.metadata)
def __getitem__(self, idx):
path = os.path.join(self.data_dir, self.metadata.get_column('path')[idx])
img = iio.imread(path)
species_name = self.metadata.get_column('species_name')[idx]
species_id = self.metadata.get_column('species_id')[idx]
photographer = self.metadata.get_column('photographer')[idx]
return {
'img': img,
'species_name': species_name,
'species_id': species_id,
'photographer': photographer,
}
nabirds_train = NABirdsDataset(metadata_train, cleaned_img_dir)
nabirds_val = NABirdsDataset(metadata_val, cleaned_img_dir)
class Normalize(grain.MapTransform):
def map(self, element):
img = element['img']
mean = np.array([0.5, 0.5, 0.5], dtype=np.float32)
std = np.array([0.5, 0.5, 0.5], dtype=np.float32)
img = img.astype(np.float32) / 255.0
img_norm = (img - mean) / std
element['img'] = img_norm
return element
class ToFloat(grain.MapTransform):
def map(self, element):
element['img'] = element['img'].astype(np.float32) / 255.0
return element
key = random.key(31)
key, subkey1, subkey2, subkey3, subkey4 = random.split(key, num=5)
class RandomCrop(grain.MapTransform):
def map(self, element):
element['img'] = pix.random_crop(
key=subkey1,
image=element['img'],
crop_sizes=(224, 224, 3)
)
return element
class RandomFlip(grain.MapTransform):
def map(self, element):
element['img'] = pix.random_flip_left_right(
key=subkey2,
image=element['img']
)
return element
class RandomContrast(grain.MapTransform):
def map(self, element):
element['img'] = pix.random_contrast(
key=subkey3,
image=element['img'],
lower=0.8,
upper=1.2
)
return element
class RandomGamma(grain.MapTransform):
def map(self, element):
element['img'] = pix.random_gamma(
key=subkey4,
image=element['img'],
min_gamma=0.6,
max_gamma=1.2
)
return element
class ZScore(grain.MapTransform):
def map(self, element):
img = element['img']
mean = np.array([0.5, 0.5, 0.5], dtype=np.float32)
std = np.array([0.5, 0.5, 0.5], dtype=np.float32)
img = (img - mean) / std
element['img'] = img
return element
seed = 123
train_batch_size = 32
val_batch_size = 2 * train_batch_size
train_sampler = grain.IndexSampler(
num_records=len(nabirds_train),
shuffle=True,
seed=seed,
shard_options=grain.NoSharding(),
num_epochs=1
)
train_loader = grain.DataLoader(
data_source=nabirds_train,
sampler=train_sampler,
operations=[
ToFloat(),
RandomCrop(),
RandomFlip(),
RandomContrast(),
RandomGamma(),
ZScore(),
grain.Batch(train_batch_size, drop_remainder=True)
]
)
val_sampler = grain.IndexSampler(
num_records=len(nabirds_val),
shuffle=False,
seed=seed,
shard_options=grain.NoSharding(),
num_epochs=1
)
val_loader = grain.DataLoader(
data_source=nabirds_val,
sampler=val_sampler,
operations=[
Normalize(),
grain.Batch(val_batch_size)
]
)Model and training strategy
In this section, we think about what deep learning technique, what model architecture, what weights, what specific packages to use for our classification task.
Then we create our model.
Our strategy
Technique
Training a model from scratch (starting with random weights) is a loss of time and computing resources. The overall technique that we need to apply is transfer learning—that is, starting from weights pre-trained on a task similar to ours.
Architecture
Options that would make sense for our example include ResNet, EfficientNet, and ViT.
ResNet
ResNet, or residual network, is a type of architecture in which the layers are reformulated as learning residual functions with reference to the layer inputs. This allows for deeper (and thus more performant) networks [1]. This is the oldest of the options that make sense for us, but it is also the most robust.
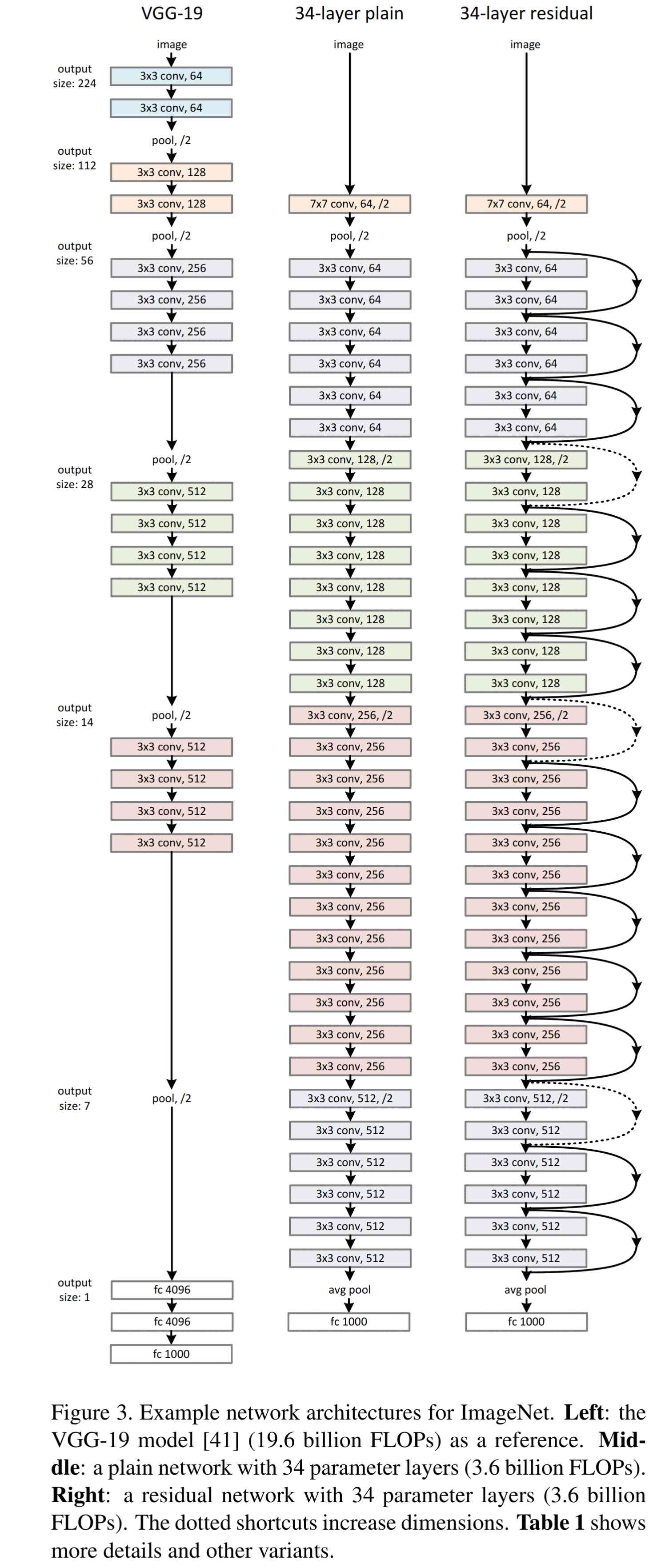
ResNet-50 is available from Hugging Face and has become a classic CNN for image classification.
EfficientNet
EfficientNet is a family of newer computer vision CNNs from Google that uses a compound coefficient to uniformly scale depth, width, and resolution of networks and achieves better accuracy with fewer parameters than other CNNs [2]. This makes them easier to train on fewer resources and can lead to better results. Tuning them is however harder than the more robust ResNet family.
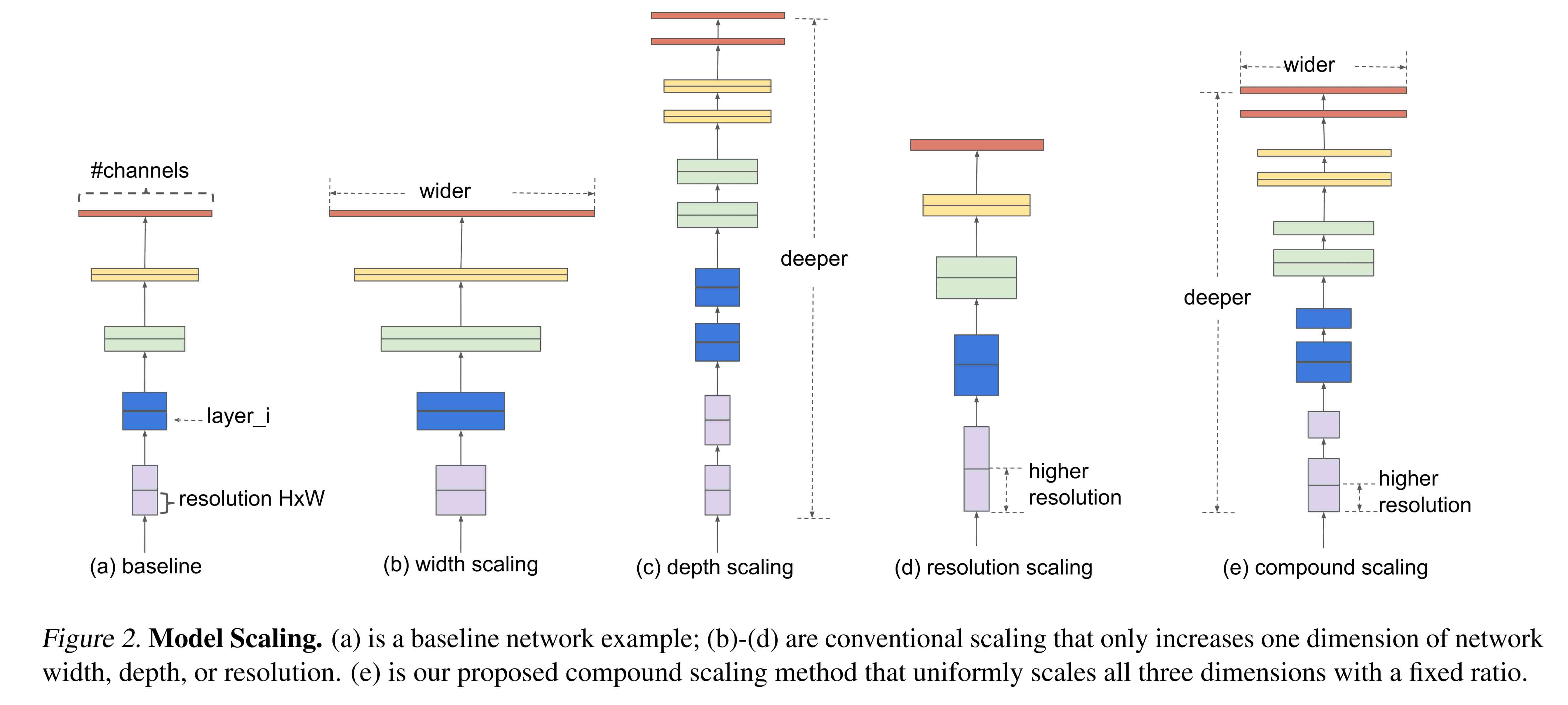
There are variations for different image sizes sizes, all available in Hugging Face. For instance:
- EfficientNet b0 for images of size 224x224
- EfficientNet b2 for images 260x260
- EfficientNet b3 for images 300x300
- EfficientNet b7 for images 600x600
ViT
While the other options were CNN, ViT, or vision transformer, is a transformer architecture (initially created for NLP tasks) applied to computer vision tasks [3]. This is a more recent technique that attains excellent results while training substantially fewer computational resources.
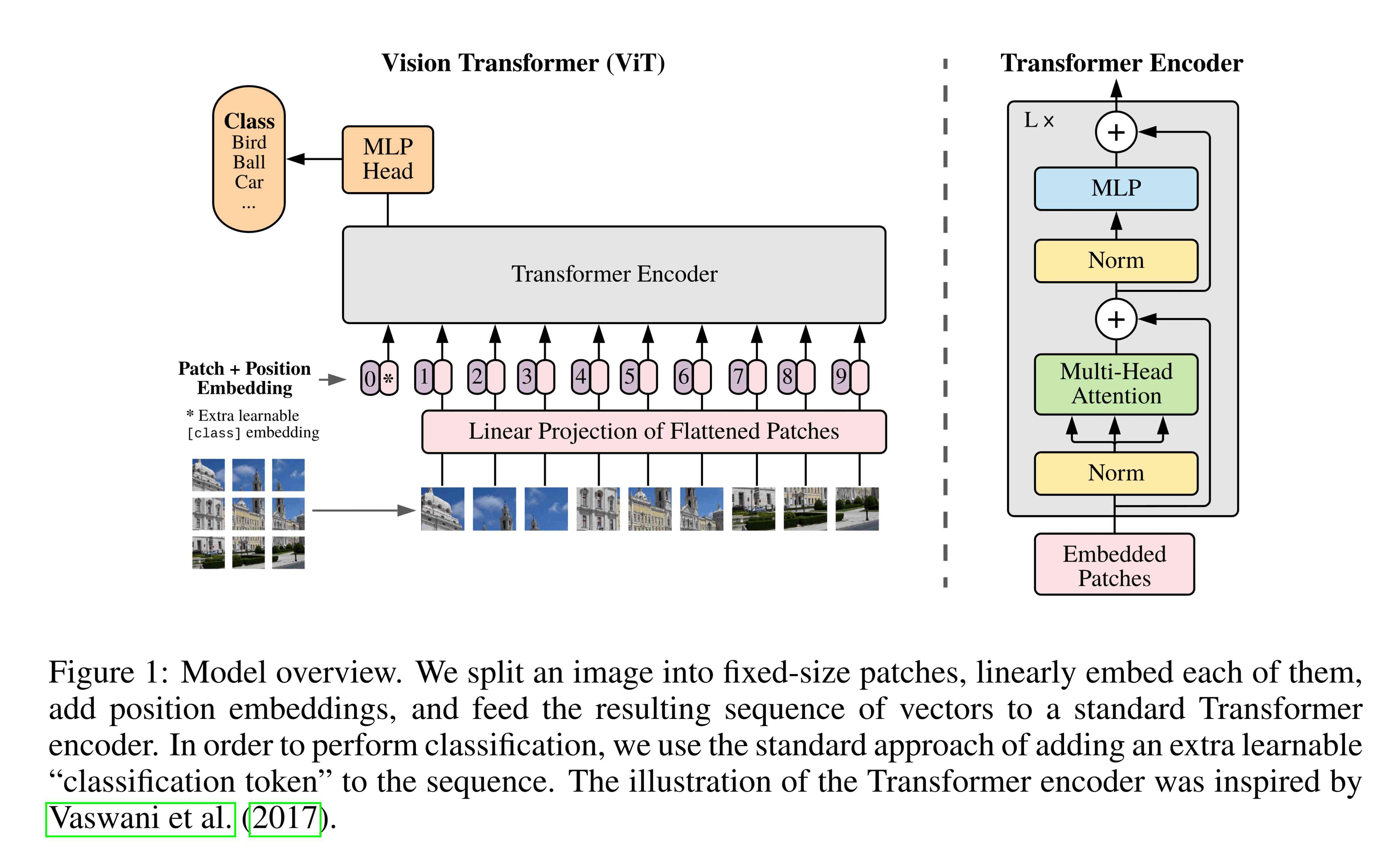
ViT is available in Hugging Face.
Which one to choose depends on the available hardware, libraries in the framework you want to use, and other practical considerations. If time permits, this is a good case of experiment tracking with MLflow.
We will go with the ViT option.
But we have a problem.
Flax is the neural network library in the JAX AI stack. It comes with an older, challenging API called Linen and a more recent, easier, more Pythonic API called NNX. We want to use the latter.
The problem is that Hugging Face Transformers has a Flax ViT model with a classification head (transformers.FlaxViTForImageClassification) which is exactly what we want, but it was built with the old Flax Linen API and there is no pretrained model built with NNX. So we need to build a ViT model from scratch with the NNX API and transfer the weights from the Linen ViT.
After that, we can fine-tune with our dataset.
Pre-trained weights
We are doing fine-grained specialized image classification. An obvious place to start are weights pretrained on some general image classification dataset. The classic such dataset is ImageNet[4].
Strategy summary
Here is our plan:
| Category | Our choice |
|---|---|
| Overall technique | Transfer learning |
| Architecture | ViT with Flax NNX |
| Pre-trained weights | Trained on ImageNet-21k |
| ViT for which we can get the pre-trained weights | transformers.FlaxViTForImageClassification |
Implementation
This part of the course draws from the ViT for image classification tutorial.
Define the model with Flax NNX
First we define a ViT architecture from scratch using the Flax NNX API. The tutorial we draw from here itself uses the original JAX-based implementation of the ViT as described in [3].
import jax
import jax.numpy as jnp
from flax import nnx
class TransformerEncoder(nnx.Module):
"""
A single transformer encoder block in the ViT model.
Args:
hidden_size (int): Input/output embedding dimensionality.
mlp_dim (int): Dimension of the feed-forward/MLP block hidden layer.
num_heads (int): Number of attention heads.
dropout_rate (float): Dropout rate. Defaults to 0.0.
rngs (flax.nnx.Rngs): A set of named `flax.nnx.RngStream` objects
that generate a stream of JAX pseudo-random number generator (PRNG) keys.
Defaults to `flax.nnx.Rngs(0)`.
"""
def __init__(
self,
hidden_size: int,
mlp_dim: int,
num_heads: int,
dropout_rate: float = 0.0,
*,
rngs: nnx.Rngs = nnx.Rngs(0),
) -> None:
# First layer normalization using `flax.nnx.LayerNorm`
# before we apply Multi-Head Attentn.
self.norm1 = nnx.LayerNorm(hidden_size, rngs=rngs)
# The Multi-Head Attention layer (using `flax.nnx.MultiHeadAttention`).
self.attn = nnx.MultiHeadAttention(
num_heads=num_heads,
in_features=hidden_size,
dropout_rate=dropout_rate,
broadcast_dropout=False,
decode=False,
deterministic=False,
rngs=rngs,
)
# Second layer normalization using `flax.nnx.LayerNorm`.
self.norm2 = nnx.LayerNorm(hidden_size, rngs=rngs)
# The MLP for point-wise feedforward
# (using `flax.nnx.Sequential`, `flax.nnx.Linear, flax.nnx.Dropout`)
# with the GeLU activation function (`flax.nnx.gelu`).
self.mlp = nnx.Sequential(
nnx.Linear(hidden_size, mlp_dim, rngs=rngs),
nnx.gelu,
nnx.Dropout(dropout_rate, rngs=rngs),
nnx.Linear(mlp_dim, hidden_size, rngs=rngs),
nnx.Dropout(dropout_rate, rngs=rngs),
)
# The forward pass through the transformer encoder block.
def __call__(self, x: jax.Array) -> jax.Array:
# The Multi-Head Attention layer with layer normalization.
x = x + self.attn(self.norm1(x))
# The feed-forward network with layer normalization.
x = x + self.mlp(self.norm2(x))
return x
class VisionTransformer(nnx.Module):
""" Implements the ViT model, inheriting from `flax.nnx.Module`.
Args:
num_classes (int): Number of classes in the classification.
Defaults to 1000.
in_channels (int): Number of input channels in the image (such as 3 for RGB).
Defaults to 3.
img_size (int): Input image size. Defaults to 224.
patch_size (int): Size of the patches extracted from the image.
Defaults to 16.
num_layers (int): Number of transformer encoder layers.
Defaults to 12.
num_heads (int): Number of attention heads in each transformer layer.
Defaults to 12.
mlp_dim (int): Dimension of the hidden layers in the feed-forward/MLP block.
Defaults to 3072.
hidden_size (int): Dimensionality of the embedding vectors.
Defaults to 3072.
dropout_rate (int): Dropout rate (for regularization). Defaults to 0.1.
rngs (flax.nnx.Rngs): A set of named `flax.nnx.RngStream` objects that
generate a stream of JAX pseudo-random number generator (PRNG) keys.
Defaults to `flax.nnx.Rngs(0)`.
"""
def __init__(
self,
num_classes: int = 1000,
in_channels: int = 3,
img_size: int = 224,
patch_size: int = 16,
num_layers: int = 12,
num_heads: int = 12,
mlp_dim: int = 3072,
hidden_size: int = 768,
dropout_rate: float = 0.1,
*,
rngs: nnx.Rngs = nnx.Rngs(0),
):
# Calculate the number of patches generated from the image.
n_patches = (img_size // patch_size) ** 2
# Patch embeddings:
# - Extracts patches from the input image and maps them to embedding vectors
# using `flax.nnx.Conv` (convolutional layer).
self.patch_embeddings = nnx.Conv(
in_channels,
hidden_size,
kernel_size=(patch_size, patch_size),
strides=(patch_size, patch_size),
padding='VALID',
use_bias=True,
rngs=rngs,
)
# Positional embeddings (add information about image patch positions):
# Set the truncated normal initializer
# (using `jax.nn.initializers.truncated_normal`).
initializer = jax.nn.initializers.truncated_normal(stddev=0.02)
# The learnable parameter for positional embeddings (using `flax.nnx.Param`).
self.position_embeddings = nnx.Param(
initializer(rngs.params(), (1, n_patches + 1, hidden_size), jnp.float32)
) # Shape `(1, n_patches +1, hidden_size`)
# The dropout layer.
self.dropout = nnx.Dropout(dropout_rate, rngs=rngs)
# CLS token (a special token prepended to the sequence of patch embeddings)
# using `flax.nnx.Param`.
self.cls_token = nnx.Param(jnp.zeros((1, 1, hidden_size)))
# Transformer encoder (a sequence of encoder blocks for feature extraction).
# - Create multiple Transformer encoder blocks (with `nnx.Sequential`
# and `TransformerEncoder(nnx.Module)` which is defined later).
self.encoder = nnx.Sequential(*[
TransformerEncoder(
hidden_size, mlp_dim, num_heads, dropout_rate, rngs=rngs
)
for i in range(num_layers)
])
# Layer normalization with `flax.nnx.LayerNorm`.
self.final_norm = nnx.LayerNorm(hidden_size, rngs=rngs)
# Classification head (maps the transformer encoder to class probabilities).
self.classifier = nnx.Linear(hidden_size, num_classes, rngs=rngs)
# The forward pass in the ViT model.
def __call__(self, x: jax.Array) -> jax.Array:
# Image patch embeddings.
# Extract image patches and embed them.
patches = self.patch_embeddings(x)
# Get the batch size of image patches.
batch_size = patches.shape[0]
# Reshape the image patches.
patches = patches.reshape(batch_size, -1, patches.shape[-1])
# Replicate the CLS token for each image with `jax.numpy.tile`
# by constructing an array by repeating `cls_token`
# along `[batch_size, 1, 1]` dimensions.
cls_token = jnp.tile(self.cls_token, [batch_size, 1, 1])
# Concatenate the CLS token and image patch embeddings.
x = jnp.concat([cls_token, patches], axis=1)
# Create embedded patches by adding positional embeddings
# to the concatenated CLS token and image patch embeddings.
embeddings = x + self.position_embeddings
# Apply the dropout layer to embedded patches.
embeddings = self.dropout(embeddings)
# Transformer encoder blocks.
# Process the embedded patches through the transformer encoder layers.
x = self.encoder(embeddings)
# Apply layer normalization
x = self.final_norm(x)
# Extract the CLS token (first token),
# which represents the overall image embedding.
x = x[:, 0]
# Predict class probabilities based on the CLS token embedding.
return self.classifier(x)Quick test to make sure the predictions have an expected shape:
# Let's define some x array made of ones
# for a 32 batch size, 224x224 images, and 3 colour layers:
x = jnp.ones((32, 224, 224, 3))
model = VisionTransformer(num_classes=1000)
y = model(x)
print('Predictions shape: ', y.shape)Predictions shape: (32, 1000)Load pretrained weights
The Hugging Face Transformers package allows to load models and pretrained weights from the Hugging Face Models Hub—the largest repository of open-weights models.
We use it to import the ViT model built with the old Flax Linen API:
from transformers import FlaxViTForImageClassificationThen we load weights pretrained on ImageNet-21k at the 224x224 resolution from the Hugging Face Models Hub:
tf_model = FlaxViTForImageClassification.from_pretrained('google/vit-base-patch16-224')Note the warning about Transformers stopping support for TensorFlow and JAX starting at version 5. This is why we pinned the package at version 4 when we installed it.
Now we copy the weights to our ViT model, reshaping layers to match the new architecture:
def vit_inplace_copy_weights(*, src_model, dst_model):
assert isinstance(src_model, FlaxViTForImageClassification)
assert isinstance(dst_model, VisionTransformer)
tf_model_params = src_model.params
tf_model_params_fstate = nnx.traversals.flatten_mapping(tf_model_params)
# Notice the use of `flax.nnx.state`.
flax_model_params = nnx.state(dst_model, nnx.Param)
flax_model_params_fstate = dict(flax_model_params.flat_state())
# Mapping from Flax parameter names to TF parameter names.
params_name_mapping = {
('cls_token',): ('vit', 'embeddings', 'cls_token'),
('position_embeddings',): ('vit', 'embeddings', 'position_embeddings'),
**{
('patch_embeddings', x): (
'vit', 'embeddings', 'patch_embeddings', 'projection', x
)
for x in ['kernel', 'bias']
},
**{
('encoder', 'layers', i, 'attn', y, x): (
'vit', 'encoder', 'layer', str(i), 'attention', 'attention', y, x
)
for x in ['kernel', 'bias']
for y in ['key', 'value', 'query']
for i in range(12)
},
**{
('encoder', 'layers', i, 'attn', 'out', x): (
'vit', 'encoder', 'layer', str(i), 'attention', 'output', 'dense', x
)
for x in ['kernel', 'bias']
for i in range(12)
},
**{
('encoder', 'layers', i, 'mlp', 'layers', y1, x): (
'vit', 'encoder', 'layer', str(i), y2, 'dense', x
)
for x in ['kernel', 'bias']
for y1, y2 in [(0, 'intermediate'), (3, 'output')]
for i in range(12)
},
**{
('encoder', 'layers', i, y1, x): (
'vit', 'encoder', 'layer', str(i), y2, x
)
for x in ['scale', 'bias']
for y1, y2 in [('norm1', 'layernorm_before'), ('norm2', 'layernorm_after')]
for i in range(12)
},
**{
('final_norm', x): ('vit', 'layernorm', x)
for x in ['scale', 'bias']
},
**{
('classifier', x): ('classifier', x)
for x in ['kernel', 'bias']
}
}
nonvisited = set(flax_model_params_fstate.keys())
for key1, key2 in params_name_mapping.items():
assert key1 in flax_model_params_fstate, key1
assert key2 in tf_model_params_fstate, (key1, key2)
nonvisited.remove(key1)
src_value = tf_model_params_fstate[key2]
if key2[-1] == 'kernel' and key2[-2] in ('key', 'value', 'query'):
shape = src_value.shape
src_value = src_value.reshape((shape[0], 12, 64))
if key2[-1] == 'bias' and key2[-2] in ('key', 'value', 'query'):
src_value = src_value.reshape((12, 64))
if key2[-4:] == ('attention', 'output', 'dense', 'kernel'):
shape = src_value.shape
src_value = src_value.reshape((12, 64, shape[-1]))
dst_value = flax_model_params_fstate[key1]
assert src_value.shape == dst_value.value.shape, (
key2, src_value.shape, key1, dst_value.value.shape
)
dst_value.value = src_value.copy()
assert dst_value.value.mean() == src_value.mean(), (
dst_value.value, src_value.mean()
)
assert len(nonvisited) == 0, nonvisited
# Notice the use of `flax.nnx.update` and `flax.nnx.State`.
nnx.update(dst_model, nnx.State.from_flat_path(flax_model_params_fstate))
vit_inplace_copy_weights(src_model=tf_model, dst_model=model)Verify weights transfer
To make sure the weights pretrained on ImageNet got transferred successfully to our ViT model, we perform inference on a single image (that I added to my website to make it easily available at a URL) using both the original model from Transformers and our model so that we can compare the two:
import matplotlib.pyplot as plt
from transformers import ViTImageProcessor
from PIL import Image
import requests
url = "https://mint.westdri.ca/ai/jxai/img/polarbears.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="np")
outputs = tf_model(**inputs)
logits = outputs.logits
model.eval()
x = jnp.transpose(inputs["pixel_values"], axes=(0, 2, 3, 1))
output = model(x)
# Model predicts one of the 1000 ImageNet classes.
ref_class_idx = logits.argmax(-1).item()
pred_class_idx = output.argmax(-1).item()
assert jnp.abs(logits[0, :] - output[0, :]).max() < 0.1
fig, axs = plt.subplots(1, 2, figsize=(6.9, 9))
for ax in axs:
ax.axis('off')
plt.tight_layout()
axs[0].set_title(
f"""
Reference model:
{tf_model.config.id2label[ref_class_idx]}
p={nnx.softmax(logits, axis=-1)[0, ref_class_idx]:.3f}
""",
fontsize=8
)
axs[0].imshow(image)
axs[1].set_title(
f"""
Our model:
{tf_model.config.id2label[pred_class_idx]}
p={nnx.softmax(output, axis=-1)[0, pred_class_idx]:.3f}
""",
fontsize=8
)
axs[1].imshow(image)
picture by Paul Zizka
Our model gives similar results; the weights transfer worked.
Adjust classifier
We do not have 1000 classes (the default for our ViT model), but 405 (the bird species in our dataset). So we replace the classifier with a fully-connected layer returning 405 classes:
model.classifier = nnx.Linear(model.classifier.in_features, 405, rngs=nnx.Rngs(0))Make sure the predictions shape with our tiny example from earlier got adjusted:
x = jnp.ones((32, 224, 224, 3))
y = model(x)
print("Predictions shape: ", y.shape)Predictions shape: (32, 405)Display model
nnx.display(model)References
1.
He K, Zhang X, Ren S, Sun J (2015) Deep residual learning for image recognition
2.
Tan M, Le QV (2020) EfficientNet: Rethinking model scaling for convolutional neural networks
3.
Dosovitskiy A, Beyer L, Kolesnikov A, et al (2021) An image is worth 16x16 words: Transformers for image recognition at scale
4.
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. Ieee, pp 248–255