GPU programming concepts
This section covers a few basic concepts of GPU programming so that you get a better idea of what is going on behind the scene when you use high-level GPU frameworks.
CPU vs GPU architecture
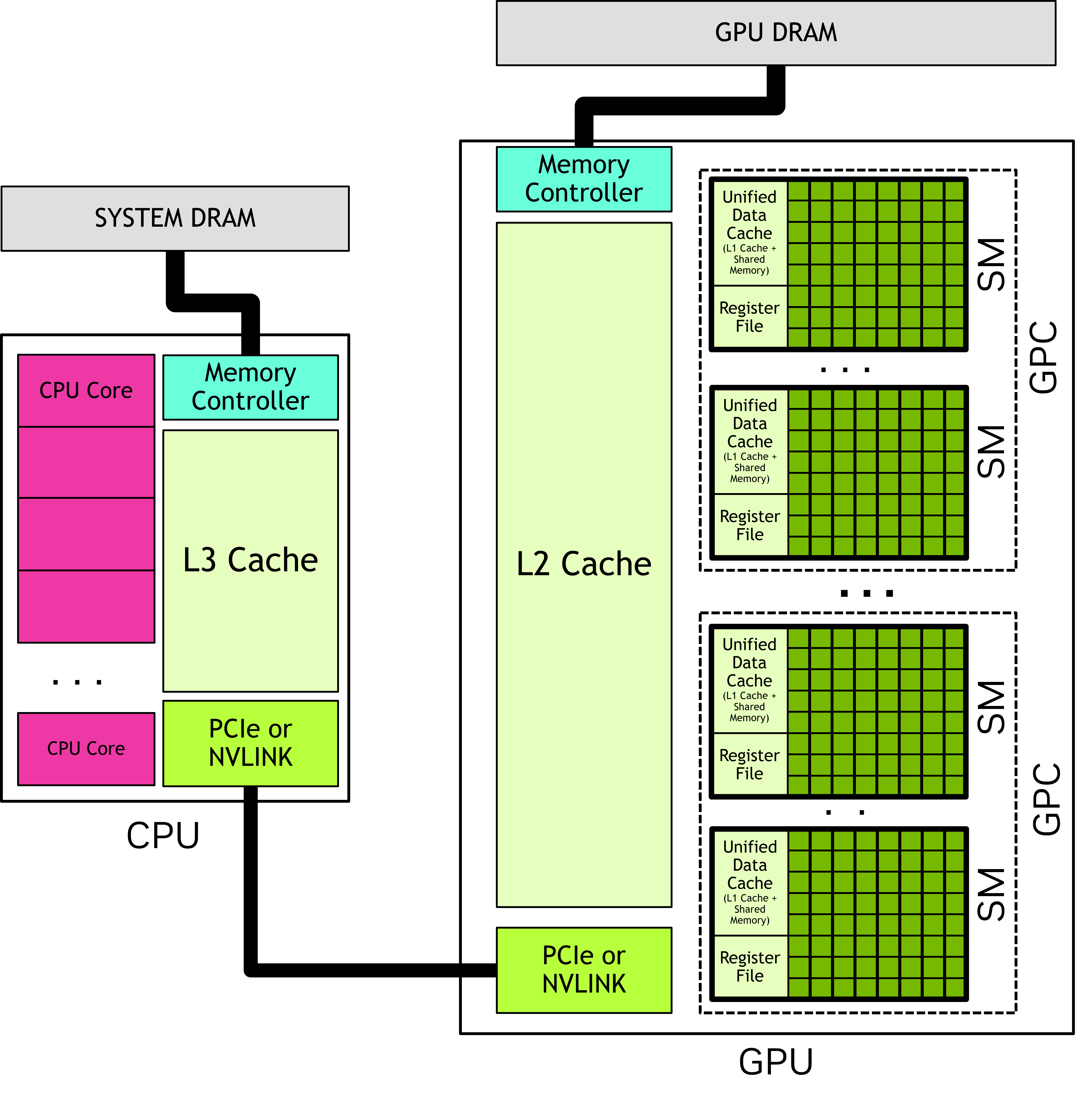
SM: Streaming multiprocessors
Collections of thread blocks (each thread block is itself a collection of threads).
GPC: Graphics Processing Clusters
Collections of SMs.
DRAM: Dynamic random access memory or dynamic RAM
The DRAM of a GPU is called the global memory because it is accessible to all SMs in that GPU.
But it is only “global” to that GPU.
Caches
Caches on chips are hierarchical.
| Cache | Speed | In CPUs | In GPUs |
|---|---|---|---|
| L1 | Fastest | One inside each CPU core | One per SM |
| L2 | A little slower | One near each CPU core1 | A single L2 shared among all SMs |
| L3 | Even slower2 | One shared among all cores | GPUs do not have an L3 cache |
1 They serve as a buffer between L1s and the L3.
2 But still much faster than the DRAM.
Programming model
The CUDA programming guide is a great place to learn the principles of CUDA programming. Alternative kernel-based frameworks (e.g. HIP, OpenCL), have a similar functioning.
Host/device
| Terminology | Explanation |
|---|---|
| Host | CPU |
| Host memory or system memory | CPU memory |
| Current device | GPU |
| Device memory | GPU memory |
| Device code | Code running on GPU |
| Kernel | Function executed on GPU |
Execution
CUDA follows a heterogeneous programming model in which it manages both CPU and GPU memory.
Here is how execution happens:
- The code starts on the host.
- CUDA APIs copy data from the host memory to the current device memory.
- Kernels (GPU functions) are executed in parallel on the device: many GPU threads run computations in an SIMT (Single Instruction, Multiple Threads) fashion.
- Finally, CUDA APIs copy the data back to the host memory.
Threads/warps/blocks/grids
Applications launch kernels on vast numbers of threads.
These threads are organized into groups of 32 called warps which are themselves organized into thread blocks which are optionally organized into clusters which are themselves organized into a grid.
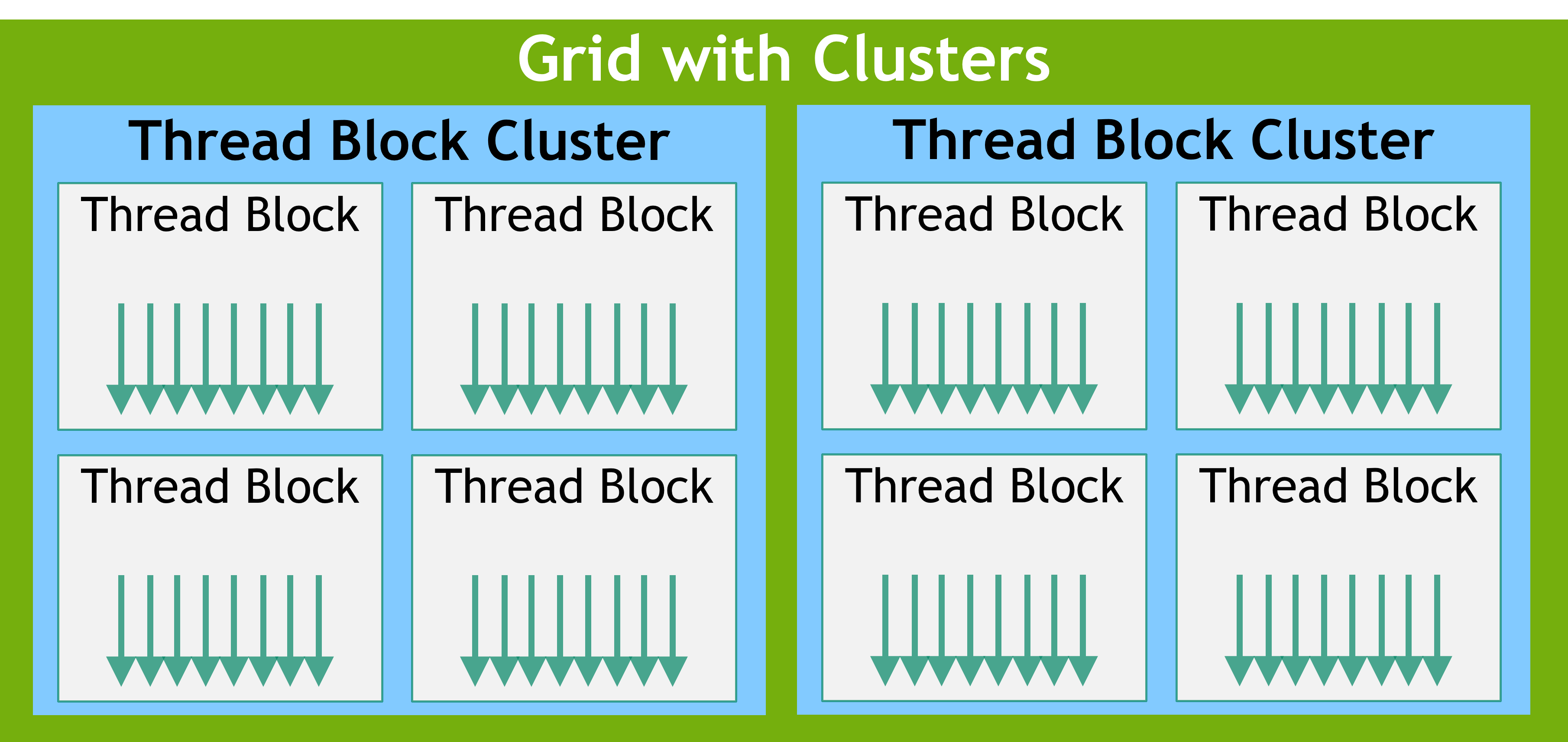
Warps execute code following a Single-Instruction Multiple-Threads (SIMT) paradigm.
Because there are 32 threads per warp, it is best to specify thread blocks with a number of threads which is a multiple of 32. Otherwise the last warp of the thread block will have some lanes that are unused, leading to suboptimal GPU utilization.
This is why batch sizes in deep learning are often multiples of 32.
This is also why choosing 256 threads per block is so common in GPU programming (256 is a multiple of 32).
Scheduling
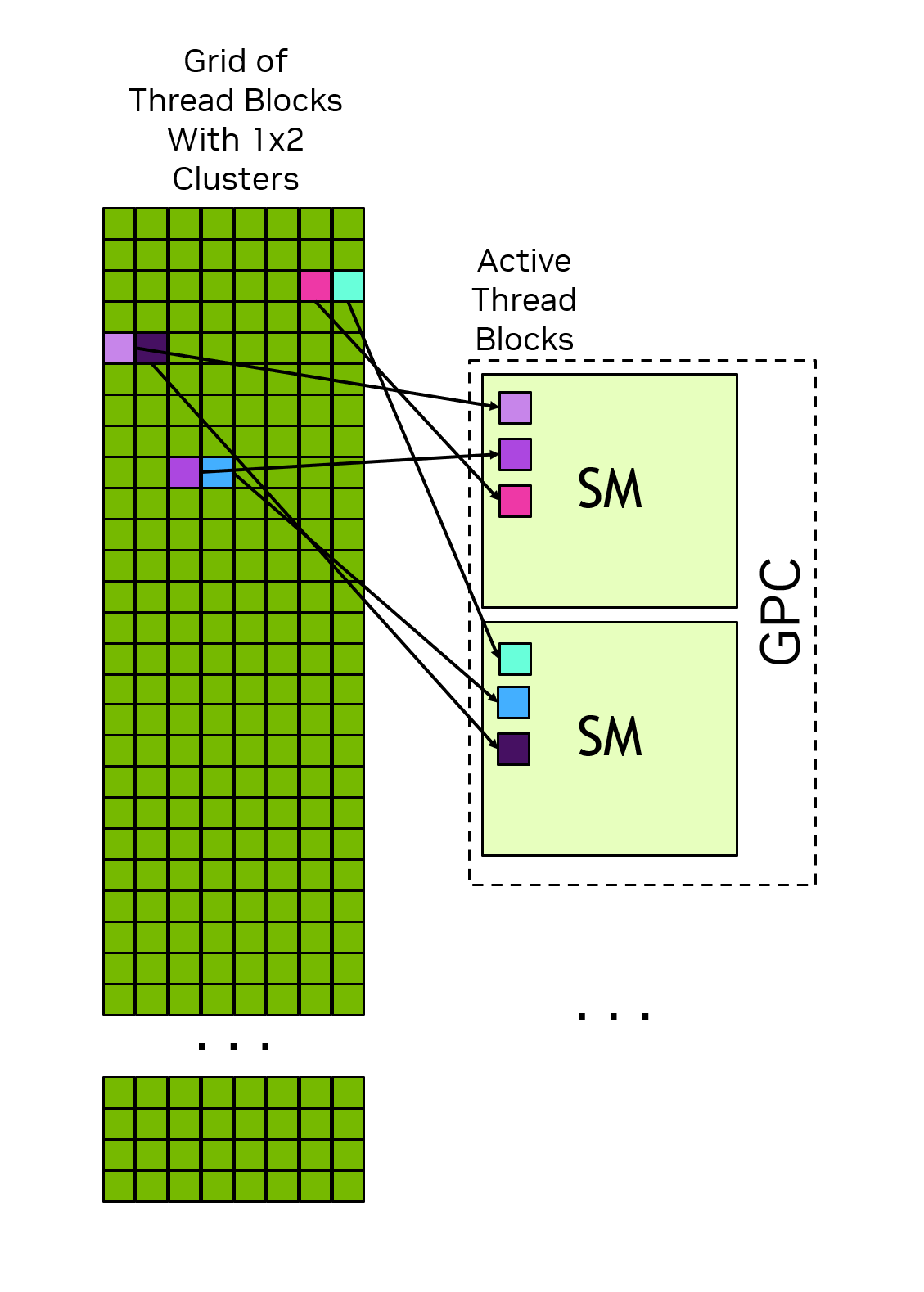
All threads of a thread block are executed in the same SM and can thus communicate using that SM L1 cache.
All thread blocks in a cluster are executed in the same GPC and can communicate and synchronize with each other using CUDA software interfaces.
Multiple GPUs
When you have multiple GPUs on a computer or compute node, the NVIDIA driver queries the motherboard and orders the GPUs based on their PCIe Bus ID (their physical slot on the motherboard). The GPU in the lowest PCIe slot becomes physical GPU 0, the next becomes 1, and so on.
By default, the current device is GPU 0, but you can set the current device to another GPU programmatically.
Streams
In CUDA, a stream is a queue of operations to perform on the GPU.
Operations placed in the same stream execute sequentially, in the order in which they were added to the queue.
Note that this does not mean that the code isn’t running in parallel! Each operation within the queue runs on a vast number of threads.
If you launch operations on multiple streams, they can be executed concurrently.