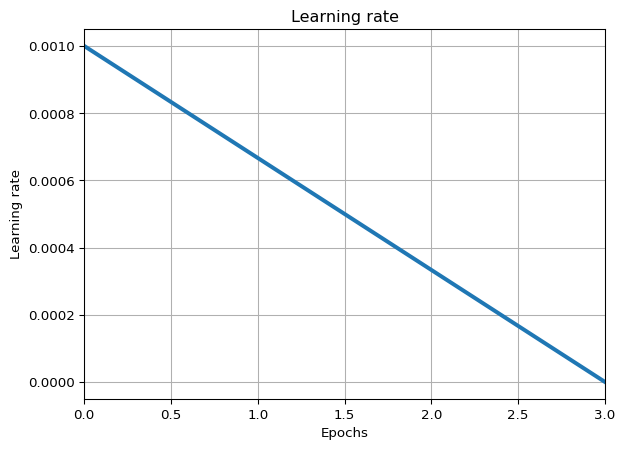
In this section, we set the hyperparameters that will be used during training: the optimizer, the loss function, the number of epochs, the momentum, the initial learning rate and a learning rate schedule, the training and evaluation steps, and the metrics to evaluate training.
Context
Minimal necessary code from previous sections
from datasets import load_datasetimport numpy as npfrom torchvision.transforms import v2 as Timport grain.python as grainimport jaximport jax.numpy as jnpfrom flax import nnxfrom transformers import FlaxViTForImageClassificationtrain_size =5*750val_size =5*250train_dataset = load_dataset("food101", split=f"train[:{train_size}]")val_dataset = load_dataset("food101", split=f"validation[:{val_size}]")labels_mapping = {}index =0for i inrange(0, len(val_dataset), 250): label = val_dataset[i]["label"]if label notin labels_mapping: labels_mapping[label] = index index +=1inv_labels_mapping = {v: k for k, v in labels_mapping.items()}img_size =224def to_np_array(pil_image):return np.asarray(pil_image.convert("RGB"))def normalize(image): mean = np.array([0.5, 0.5, 0.5], dtype=np.float32) std = np.array([0.5, 0.5, 0.5], dtype=np.float32) image = image.astype(np.float32) /255.0return (image - mean) / stdtv_train_transforms = T.Compose([ T.RandomResizedCrop((img_size, img_size), scale=(0.7, 1.0)), T.RandomHorizontalFlip(), T.ColorJitter(0.2, 0.2, 0.2), T.Lambda(to_np_array), T.Lambda(normalize),])tv_test_transforms = T.Compose([ T.Resize((img_size, img_size)), T.Lambda(to_np_array), T.Lambda(normalize),])def get_transform(fn):def wrapper(batch): batch["image"] = [ fn(pil_image) for pil_image in batch["image"] ] batch["label"] = [ labels_mapping[label] for label in batch["label"] ]return batchreturn wrappertrain_transforms = get_transform(tv_train_transforms)val_transforms = get_transform(tv_test_transforms)train_dataset = train_dataset.with_transform(train_transforms)val_dataset = val_dataset.with_transform(val_transforms)seed =12train_batch_size =32val_batch_size =2* train_batch_sizetrain_sampler = grain.IndexSampler(len(train_dataset), shuffle=True, seed=seed, shard_options=grain.NoSharding(), num_epochs=1,)val_sampler = grain.IndexSampler(len(val_dataset), shuffle=False, seed=seed, shard_options=grain.NoSharding(), num_epochs=1,)train_loader = grain.DataLoader( data_source=train_dataset, sampler=train_sampler, worker_count=4, worker_buffer_size=2, operations=[ grain.Batch(train_batch_size, drop_remainder=True), ])val_loader = grain.DataLoader( data_source=val_dataset, sampler=val_sampler, worker_count=4, worker_buffer_size=2, operations=[ grain.Batch(val_batch_size), ])class VisionTransformer(nnx.Module):def__init__(self, num_classes: int=1000, in_channels: int=3, img_size: int=224, patch_size: int=16, num_layers: int=12, num_heads: int=12, mlp_dim: int=3072, hidden_size: int=768, dropout_rate: float=0.1,*, rngs: nnx.Rngs = nnx.Rngs(0), ):# Patch and position embedding n_patches = (img_size // patch_size) **2self.patch_embeddings = nnx.Conv( in_channels, hidden_size, kernel_size=(patch_size, patch_size), strides=(patch_size, patch_size), padding="VALID", use_bias=True, rngs=rngs, ) initializer = jax.nn.initializers.truncated_normal(stddev=0.02)self.position_embeddings = nnx.Param( initializer( rngs.params(), (1, n_patches +1, hidden_size), jnp.float32 ) )self.dropout = nnx.Dropout(dropout_rate, rngs=rngs)self.cls_token = nnx.Param(jnp.zeros((1, 1, hidden_size)))# Transformer Encoder blocksself.encoder = nnx.Sequential(*[ TransformerEncoder( hidden_size, mlp_dim, num_heads, dropout_rate, rngs=rngs )for i inrange(num_layers) ])self.final_norm = nnx.LayerNorm(hidden_size, rngs=rngs)# Classification headself.classifier = nnx.Linear(hidden_size, num_classes, rngs=rngs)def__call__(self, x: jax.Array) -> jax.Array:# Patch and position embedding patches =self.patch_embeddings(x) batch_size = patches.shape[0] patches = patches.reshape(batch_size, -1, patches.shape[-1]) cls_token = jnp.tile(self.cls_token, [batch_size, 1, 1]) x = jnp.concat([cls_token, patches], axis=1) embeddings = x +self.position_embeddings embeddings =self.dropout(embeddings)# Encoder blocks x =self.encoder(embeddings) x =self.final_norm(x)# fetch the first token x = x[:, 0]# Classificationreturnself.classifier(x)class TransformerEncoder(nnx.Module):def__init__(self, hidden_size: int, mlp_dim: int, num_heads: int, dropout_rate: float=0.0,*, rngs: nnx.Rngs = nnx.Rngs(0), ) ->None:self.norm1 = nnx.LayerNorm(hidden_size, rngs=rngs)self.attn = nnx.MultiHeadAttention( num_heads=num_heads, in_features=hidden_size, dropout_rate=dropout_rate, broadcast_dropout=False, decode=False, deterministic=False, rngs=rngs, )self.norm2 = nnx.LayerNorm(hidden_size, rngs=rngs)self.mlp = nnx.Sequential( nnx.Linear(hidden_size, mlp_dim, rngs=rngs), nnx.gelu, nnx.Dropout(dropout_rate, rngs=rngs), nnx.Linear(mlp_dim, hidden_size, rngs=rngs), nnx.Dropout(dropout_rate, rngs=rngs), )def__call__(self, x: jax.Array) -> jax.Array: x = x +self.attn(self.norm1(x)) x = x +self.mlp(self.norm2(x))return xmodel = VisionTransformer(num_classes=1000)tf_model = FlaxViTForImageClassification.from_pretrained('google/vit-base-patch16-224')def vit_inplace_copy_weights(*, src_model, dst_model):assertisinstance(src_model, FlaxViTForImageClassification)assertisinstance(dst_model, VisionTransformer) tf_model_params = src_model.params tf_model_params_fstate = nnx.traversals.flatten_mapping(tf_model_params) flax_model_params = nnx.state(dst_model, nnx.Param) flax_model_params_fstate = flax_model_params.flat_state() params_name_mapping = { ("cls_token",): ("vit", "embeddings", "cls_token"), ("position_embeddings",): ("vit","embeddings","position_embeddings" ),**{ ("patch_embeddings", x): ("vit","embeddings","patch_embeddings","projection", x )for x in ["kernel", "bias"] },**{ ("encoder", "layers", i, "attn", y, x): ("vit","encoder","layer",str(i),"attention","attention", y, x )for x in ["kernel", "bias"]for y in ["key", "value", "query"]for i inrange(12) },**{ ("encoder", "layers", i, "attn", "out", x): ("vit","encoder","layer",str(i),"attention","output","dense", x )for x in ["kernel", "bias"]for i inrange(12) },**{ ("encoder", "layers", i, "mlp", "layers", y1, x): ("vit","encoder","layer",str(i), y2,"dense", x )for x in ["kernel", "bias"]for y1, y2 in [(0, "intermediate"), (3, "output")]for i inrange(12) },**{ ("encoder", "layers", i, y1, x): ("vit", "encoder", "layer", str(i), y2, x )for x in ["scale", "bias"]for y1, y2 in [ ("norm1", "layernorm_before"), ("norm2", "layernorm_after") ]for i inrange(12) },**{ ("final_norm", x): ("vit", "layernorm", x)for x in ["scale", "bias"] },**{ ("classifier", x): ("classifier", x)for x in ["kernel", "bias"] } } nonvisited =set(flax_model_params_fstate.keys())for key1, key2 in params_name_mapping.items():assert key1 in flax_model_params_fstate, key1assert key2 in tf_model_params_fstate, (key1, key2) nonvisited.remove(key1) src_value = tf_model_params_fstate[key2]if key2[-1] =="kernel"and key2[-2] in ("key", "value", "query"): shape = src_value.shape src_value = src_value.reshape((shape[0], 12, 64))if key2[-1] =="bias"and key2[-2] in ("key", "value", "query"): src_value = src_value.reshape((12, 64))if key2[-4:] == ("attention", "output", "dense", "kernel"): shape = src_value.shape src_value = src_value.reshape((12, 64, shape[-1])) dst_value = flax_model_params_fstate[key1]assert src_value.shape == dst_value.value.shape, ( key2, src_value.shape, key1, dst_value.value.shape ) dst_value.value = src_value.copy()assert dst_value.value.mean() == src_value.mean(), ( dst_value.value, src_value.mean() )assertlen(nonvisited) ==0, nonvisited nnx.update(dst_model, nnx.State.from_flat_path(flax_model_params_fstate))vit_inplace_copy_weights(src_model=tf_model, dst_model=model)model.classifier = nnx.Linear(model.classifier.in_features, 5, rngs=nnx.Rngs(0))
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)
CellIn[1], line 351 347assertlen(nonvisited)==0,nonvisited 349nnx.update(dst_model,nnx.State.from_flat_path(flax_model_params_fstate))--> 351vit_inplace_copy_weights(src_model=tf_model,dst_model=model) 353model.classifier=nnx.Linear(model.classifier.in_features,5,rngs=nnx.Rngs(0))CellIn[1], line 318, in vit_inplace_copy_weights(src_model, dst_model) 235flax_model_params_fstate=flax_model_params.flat_state() 237params_name_mapping={ 238("cls_token",):("vit","embeddings","cls_token"), 239("position_embeddings",):( (...) 315} 316}--> 318nonvisited=set(flax_model_params_fstate.keys()) 320forkey1,key2inparams_name_mapping.items(): 321assertkey1inflax_model_params_fstate,key1AttributeError: 'FlatState' object has no attribute 'keys'
Load packages
Packages and modules necessary for this section:
# to set the learning rate and optimizerimport optax# to plot the evolution of learning rateimport matplotlib.pyplot as plt
This is the part that is computationally intensive and where we want to use JAX and its efficiency. In particularly, we want to JIT-compile the functions that will do the training and evaluation.
JAX requires a strictly functional programming version of Python. This is what allows its internal representations (the Jaxprs) to perform transformations (jax.jit, jax.vmap, jax.pmap, and jax.grad and the convenience decorators @jax.jit, @jax.vmap, @jax.pmap, and @jax.grad).
Flax does not respect this anymore with the new NNX API. The JAX transformations can thus not be applied directly in Flax (as they were in the Linen API) and require adapted versions that handle objects’ states under the hood. The NNX versions of these transformations are called nnx.jit, nnx.vmap, nnx.pmap, and nnx.grad (and the convenience decorators @nnx.jit, @nnx.vmap, @nnx.pmap, and @nnx.grad).